4.1. Operations Overview#
The life cycle of observing programs, Figure 4.1 and Figure 4.2, typically begins with astronomers, who prepare and submit telescope proposals to a Time Allocation Committee (TAC) for review. In this first stage, astronomers access Observatory Tools on-line to design their experiment, to format their proposal and to gauge feasibility, which is contingent on exposure time calculations, guide star availability, AO Strehl requirements, etc. The proposals sent to GMTO are stored in the observatory program database, evaluated for technical correctness, and distributed to the TAC for review. Afterwards, decisions by the TAC return to the GMTO program database for processing and distribution back to the astronomers. Highly ranked proposals are passed on from Phase I into Phase II and stored into the operations database.
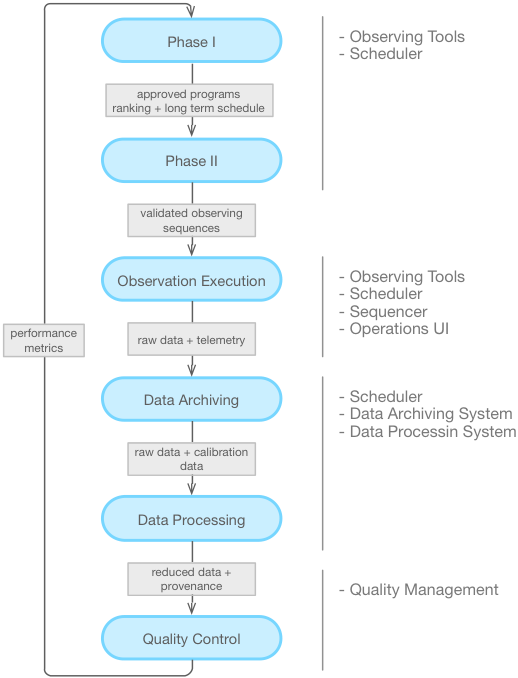
Fig. 4.1 Top level Observatory Workflow#
During Phase II of proposal preparations, data from Phase I (e.g., program description, target coordinates, basic instrument configuration, exposure time, scheduling constraints) become the starting point for observation planning. Details of observing strategies, instrument configuration, guide star selection, dither and mosaic pattern, etc., are entered into the system in a way that can be directly recalled, interpreted, and executed by the telescope control system. This process, illustrated in Figure 4.2, may iterate several (or numerous) times between an observer, the proposal validation system, and a GMTO observatory scientist until the program can satisfy technical, science, and scheduling constraints for implementation. Before execution, all the details necessary to properly carry out observations are stored permanently into the GMTO archival database to be recalled and executed by an observer.
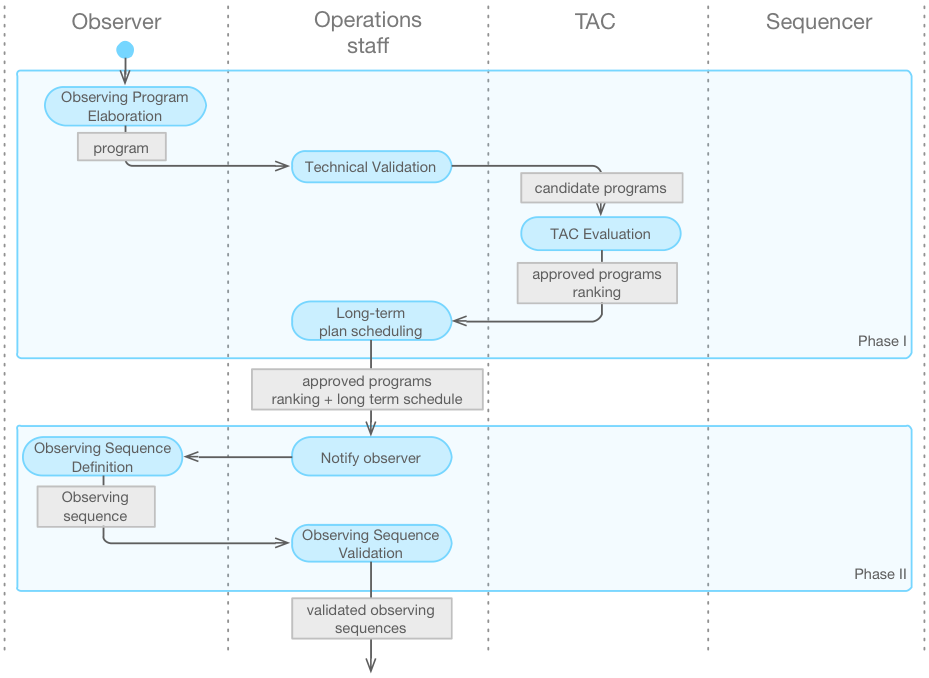
Fig. 4.2 Phase I and Phase II activity diagram#
As specified by the Operation Concept Document (OCD), GMT will have several operational modes: classical (on-site and remote), queue, and interrupt observing. All operational modes require long-term program scheduling procedures that optimize on parameters that are known a priori (moon phase, instrument availability schedule, air mass requirements, science program ranking). However, in queue mode, the different observing programs and targets get shuffled into and out of the schedule, on-the-fly, to optimize the use of telescope resources according to runtime conditions (e.g., weather, seeing, instrument behavior). Programs that do not get observed, or are only partially observed, are returned back into shorter-term, medium-term, or long-term queues. The Section on Scheduling System describes the scheduling system in more detail.
During daytime, observers, AO and instrument specialists prepare appropriate calibrations. Engineering activities (installation, configuration, calibrations, and maintenance) also occurs in the morning to mid-afternoon, conducted by observatory staff. For routine initialization and calibration procedures, customizable software sequences will expedite the process and minimize repetitive user involvement where feasible. Typically, observers or operators perform basic data calibrations for science observations to remove instrumental signatures, such as flatfielding, or for photometric or wavelength calibration, etc. Instrument calibrations are performed both in the afternoon and often throughout the night for AO, and some spectroscopic instruments that may involve moving calibration sources into and out of the telescope optical path. Pre-defined and customizable sequence and calibration procedures can facilitate if not completely automate complex processes. The Section on Sequencer describes the sequencing system in more detail.
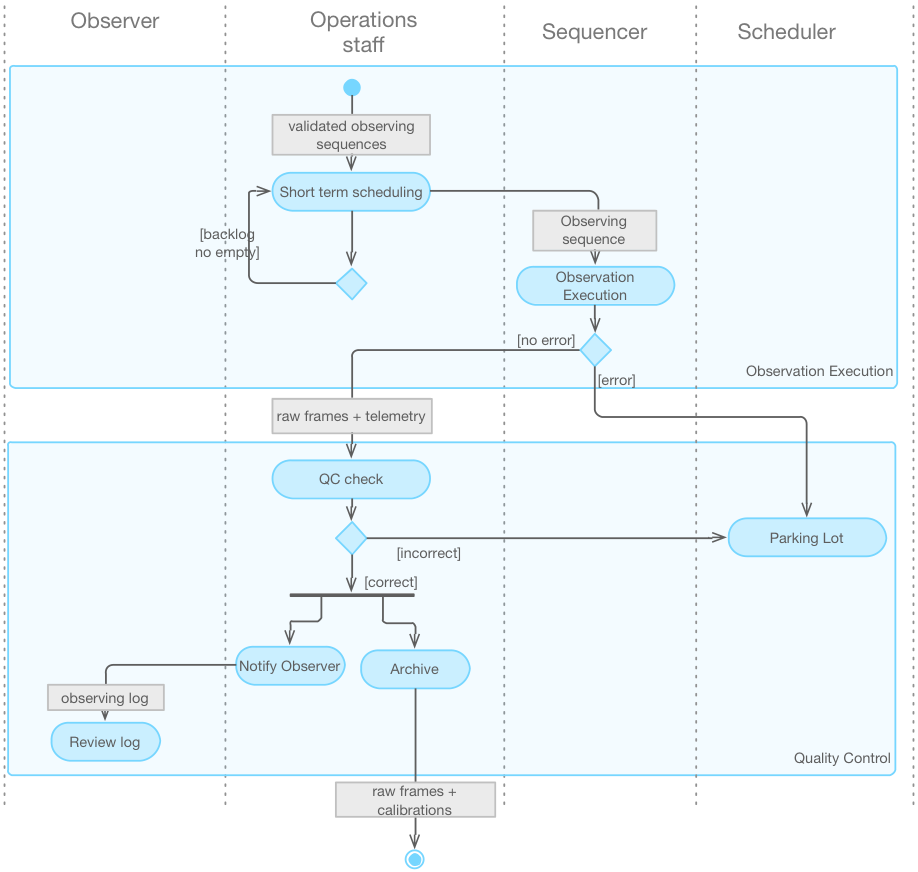
During observations (Figure %s) the telescope
operator controls and monitors the health of the telescope, instruments,
enclosure, and other facility equipment using real-time telemetry data, which is
also stored into the engineering data archive for future analysis. The observer,
who may be a visiting scientist for classical observing, or an
observatory/instrument scientist for queue observing, directs the sequence of
targets for observations based on runtime judgments of observing conditions or
from a queue scheduler. Sky visualization tools provide observers situational
awareness of their target sky trajectories throughout the night relative to
potential guide stars (for non-sidereal targets), the moon, clouds, wind
direction, and elevation, and telescope limits. During observations, a sequencer
oversees and choreographs the timing of hardware and software execution. Due to
the complexity of the GMT optical-mechanical systems, all activities that take
place during runtime operations, including all instrument and telescope
controls, and all observations, will involve a combination of sequencing and
human validation. Observers may create, customize, or augment existing,
observing sequences according to their science observing requirements, such as
commanding mosaic patterns, dithering off and on-source exposures,
starting/stopping exposure sequences, acquiring guide stars, etc.
After a science exposure is complete and read out, raw metadata and pixel data arriving from the telescope are stored into the observatory archive permanently. Simultaneously, they are automatically processed via a pipeline for data calibration. The pipeline recognizes data types based on metadata (i.e., image headers) and directs the flow of the reduction accordingly. The data calibration pipeline produces an image that is ideally free of instrumental signatures. The output may then be piped through other data pipelines, such as spectral extraction or more advanced states of image/spectroscopy combination (e.g., stacking, mosaic, data cube creation, etc.). All raw and processed data, maintenance procedures, logs, telemetry, documentation, and other instrument data, maintained and stored in the GMTO archival database, will be fully accessible and searchable.
Observing Sequence Life Cycle
The Figure below represents the states of an Observation Sequence (OS) during its life cycle. These states are the basis for the visualization of flow in the Observatory Workflow Manager, which follows the concept of a Kanban panel (i.e., a scheduling system for lean production). Table 4.2 describes the states. Although an Observation Sequence is used as example, the model extends to any kind of automated tasks. Observation Sequences are a subclass of the more generic Operation Sequence; these may automate calibration, diagnosis or other engineering Tasks.
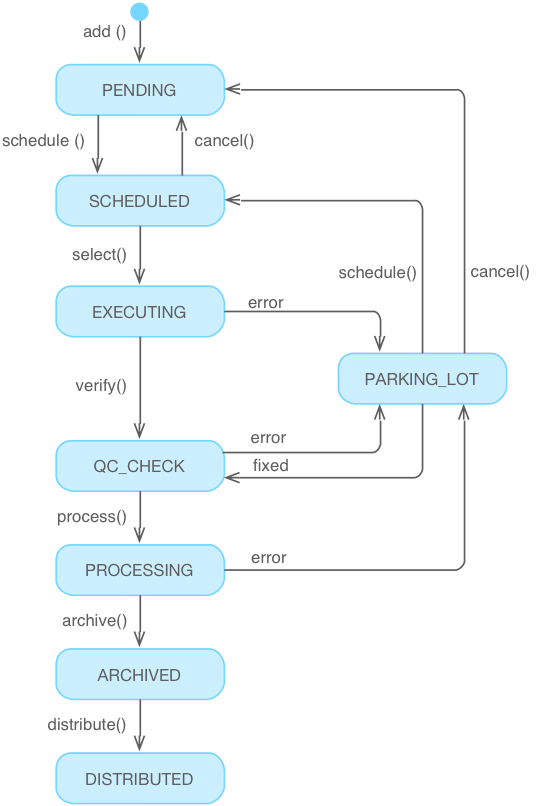
Fig. 4.3 Observation Sequence Life Cycle#
State |
Description |
|---|---|
Pending |
This is the initial state of an Observing sequence. Observing Sequences are created in the Operations Database once the Phase II proposal process is finished. This could be well in advance of the execution of the observation, or in the case of PI directed mode, could be on-the-fly. |
Scheduled |
The Observation Sequence has been selected for short-term execution. The duration of “short-term” depends on the observatory operation procedures, and could be the next night or many nights, pending long-term schedules. |
Executing |
The sequencer is executing the Observation Sequence. Should a fault occur that compromises data quality (e.g. this could be triggered by automated rules or by the system operators) the state changes provisionally to “Parking_lot” (below). The goal is to start executing the next Observing or Operation Sequence while another member of the staff diagnoses the problem. |
QC_Check |
Once an observation is finished, the data, telescope telemetry, alarms and logs are checked for basic errors. Automated error-checking rules can be defined for each Observing Sequence Template, as they may depend on the AO or Instrument Observing mode. The observational data are processed to allow for quick-look. In some observing modes, the observer may decide whether to abort or execute the next Observational Sequence, such as when an observational state has been changed to “Parking_lot” due to errors. |
Archived |
The raw data is archived as soon as they are read out from the detector. Calibration data are retrieved and prepared for further processing. |
Processing |
Raw data and calibrations are processed for a first-pass data reduction. If an error occurs during data reduction, the observational state may be changed to Parking_lot depending on the severity of the error. |
Distributed |
The raw data are distributed to remote sites (e.g. remote observer or remote operation center). An observation remains in this state until all the data have been transmitted to the intended destinations. |
Parking_lot |
This is the repository for errors that occurred during an observation. An observation is pending further analysis by a human operator. Depending on the problem and changing observing conditions, the observation can be fixed and moved further down to QC, can be included again in the short term queue, or further back into the long-term observing backlog. |