3.6. Health and Supervision#
Reliability is one of the key design drivers for the SWCS. Several principles have been used in the reference architecture to address this:
Fault detection and management is implemented as close as possible to the source.
When a component does not have enough information to take a corrective action then its supervisor is notified.
Every subsystem, not only Device Control Subsystems, has to include a supervisor that takes care of life-cycle and fault management of the Subsystem.
A general system supervisor takes care of the overall life-cycle and health status of the system.
Supervisors can implement alternative strategies when possible, to improve the fault tolerance of the system. For example, maintaining the wavefront error will require switching to degraded modes when some sensor becomes unavailable or when a communication glitch occurs.
All Components have to specify formally their fault cases by means of alarm event conditions.
All alarm events are sent to the alarm service so operators can be notified and events can be logged for further analysis.
Although the ISS is ultimately responsible for personal and equipment safety, software and control Components should attempt to prevent the occurrence of fault conditions.
The ISS is always interrogated about the status of the interlocks relative to any given Subsystem or Component.
All the components are required to sample relevant state variables using the telemetry service. Telemetry data are sent to the telemetry service so they can be monitored and correlated with other state variables of the system. Telemetry data are essential to diagnose any faulty behavior so the system can be improved.
The Logging Service allows the logging of significant event occurrences during the nominal operation of the system. Analyzing transcription logs helps understanding the behavior of the system and to detect any malfunction.
Each Subsystem Supervisor implements the following functions when applicable:
Subsystem integrity (e.g., collision avoidance)
Subsystem component configuration (e.g., components are configured in the right sequence and with the right configuration properties, look-up-tables, etc.)
Subsystem robustness (e.g., behavior in presence of non-nominal conditions, fault management and tolerance)
Subsystem life-cycle (e.g., startup and shutdown)
Subsystem embedded diagnosis
Subsystem modal transition for subsystems that have different modes of operation
Subsystem IO health
The Figure below shows the conceptual view of the Supervisory Hierarchy.
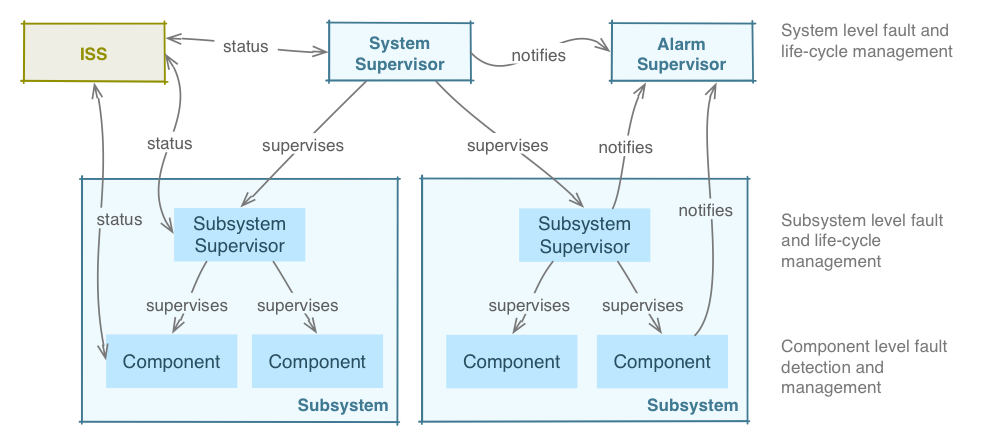
Fig. 3.7 Supervisory Hierarchy#